
موتور جستجو چگونه کار میکند؟
در پاسخ به این سوال که موتور جستجو چیست باید گفت موتور جستجو ماشین پاسخ به سوالات کاربران است. موتورهای جستجو برای تشخیص، درک و سازماندهی محتوای اینترنت طراحی شدهاند تا مرتبطترین نتایج را برای کوئریها و پرسشهای کاربران ایجاد کنند.
برای اینکه محتوای سایت شما در نتایج جستجو نمایش داده شود، اول از همه باید این محتوا برای موتورهای جستجو قابل مشاهده باشد و این، مهمترین قطعه از پازل سئو محسوب میشود چون اگر امکان پیدا کردن سایت شما وجود نداشته باشد، راهی برای نمایش آن در صفحه نتایج جستجو وجود ندارد.
موتورهای جستجو چگونه کار میکنند؟
برای آشنایی با موتورهای جستجو باید بدانید که آنها دارای سه عملکرد کلی هستند:
- خزش کردن یا خزیدن (Crawl): در این فرایند محتوای اینترنت جستجو و پیمایش شده و محتوا یا کد همه نشانیهای وب که موتور جستجو پیدا میکند، مورد تحلیل و بررسی قرار میگیرد.
- فهرست کردن (Index): محتوای پیدا شده در مرحله خزش ذخیره و سازماندهی میشود. وقتی صفحهای در فهرست ایندکس قرار گرفته باشد، وارد مرحله نمایش داده شدن برای کوئریهای مرتبط میشود.
- رتبه بندی (Rank): ارائه محتوایی که بهترین پاسخ را برای کوئری مورد نظر ایجاد کنند. یعنی نتایج به ترتیب تناسبشان برای کوئری مورد نظر مرتب میشوند.
در ادامه با این ویژگی های موتورهای جستجو بیشتر آشنا خواهید شد.
خزش موتور جستجو چیست؟
خزش (Crawling) به فرایند جستجو و اکتشافی گفته میشود که در آن موتور جستجو یک تیم از رباتها (که به آنها خزشگر یا عنکبوت گفته میشود) را مأمور پیدا کردن محتوای جدید و بروزرسانی شده میکند. این محتوا میتواند انواع مختلفی – مثل صفحه وب، عکس، ویدیو، پی دی اف و غیره – داشته باشد اما صرف نظر از فرمت آن همیشه با استفاده از لینک اکتشاف میشود.
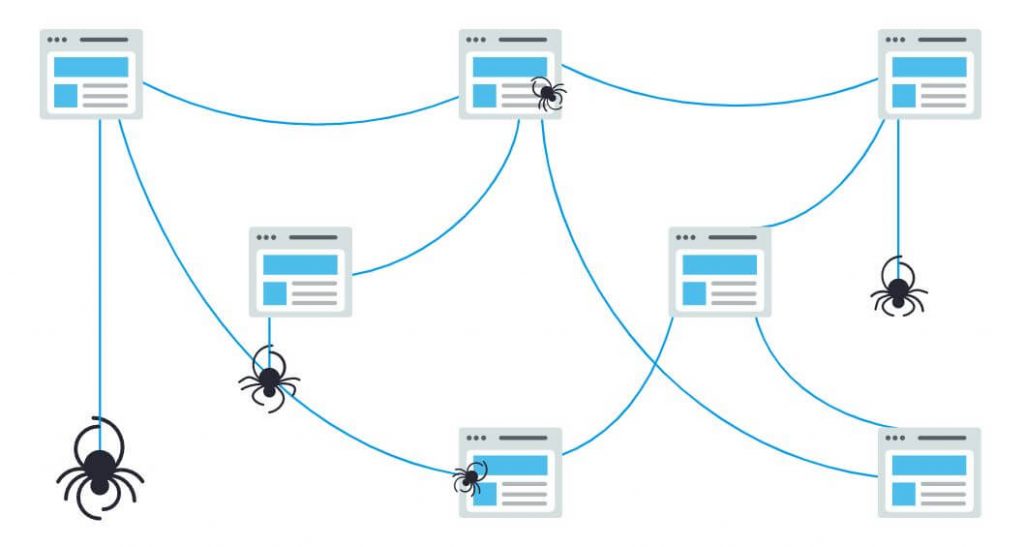
ربات گوگل کار را با واکشی (fetching) چند صفحه شروع کرده و سپس لینکهای آن صفحه را دنبال میکند تا نشانیهای (URL) جدید را پیدا کند. خزشگر میتواند با دنبال کردن مسیر این لینکها محتوای جدید را پیدا کرده و به فهرست لینکهایش که به آن کافئین گفته میشود – دیتابیسی بزرگ متشکل از URLهای شناسایی شده – اضافه کند تا بعداً وقتی کاربری در حال جستجوی اطلاعاتی باشد که این URL تطبیق خوبی با آن دارد، نمایش داده شود.
ایندکس موتور جستجو چیست؟
ایندکس (Index) به معنی اطلاعات فهرست شده است. موتورهای جستجو در مرحله ایندکس، محتوای صفحاتی که لینک آنها در مرحله قبل در فهرست خزشگر قرار گرفته را پیدا نموده، پردازش و ذخیره میکنند و دیتابیسی عظیم متشکل از همه محتوای شناسایی شده که برای نمایش به جستجوکنندهها مناسب به نظر میرسد، تشکیل میدهند که به این دیتابیس، ایندکس موتور جستجو گفته میشود.
رتبه بندی موتور جستجو
وقتی کاربری جستجویی انجام میدهد، موتورهای جستجو ایندکسهای خودشان را بررسی میکنند تا محتوای مناسب را پیدا کنند سپس این محتوا را مرتب میکنند به این امید که بتوانند کوئری جستجو کننده را حل کنند. این مرتب کردن نتایج بر حسب میزان تناسب آنها رتبه بندی نام دارد. در مجموع میتوان این طور گفت که سایتی با تناسب بیشتر برای کوئری مورد نظر، رتبه بالاتری کسب میکند.
دسترسی خزشگرها
میتوانید دسترسی خزشگرها به همه بخشهای سایت خودتان را محدود کنید یا به موتورهای جستجو دستور دهید که از ذخیره کردن بعضی صفحات در ایندکس خودشان خودداری کنند. هر چند انجام این کار دلایل خاص خودش را دارد اما اگر میخواهید کاربران قادر به پیدا کردن محتوای سایت شما باشند، اول از همه باید مطمئن باشید که خزشگرها به این اطلاعات دسترسی داشته و این محتوا قابل ایندکس شدن هستند در غیر این صورت محتوای سایت شما قابل مشاهده نخواهد بود.
در انتهای این مقاله از سایت آرکاد، اطلاعات لازم برای همکاری با موتورهای جستجو را کسب میکنید.
از نظر سئو همه موتورهای جستجو یکسان نیستند
خیلی از افراد مبتدی درباره اهمیت موتورهای جستجوی مختلف دچار تردید میشوند. اکثر ما در جریان هستیم که گوگل سهم عمدهای از بازار موتورهای جستجو را در اختیار دارد اما بهینهسازی برای موتور جستجو بینگ یا موتور جستجوگر یاهو و سایر موتورهای جستجو چقدر مهم است؟ واقعیت این است که بیش از ۳۰ موتور جستجوی مهم داریم اما جامعه سئو فقط به موتور جستجوگر گوگل توجه دارد چون اکثر کاربران وب برای جستجو از گوگل استفاده میکنند. با در نظر گرفتن سرویسهایی مثل Google Images، Google Maps و یوتیوب (که متعلق به گوگل است) متوجه میشویم که بیش از ۹۰ درصد جستجوهای وب با گوگل انجام میشوند – یعنی ۲۰ برابر بینگ و یاهو با هم، بنابراین میتوان گوگل را بعنوان بهترین موتور جستجو معرفی کرد.
شما را به یک چالش جالب دعوت میکنم. نتایج یک موتور جستجوگر خارجی مانند گوگل یا موتور جستجو aol را برای یک کلمه کلیدی خاص با نتایج موتور جستجوی فارسی مانند جستجوگر پارسی جو یا موتور جستجو پارسیک مقایسه کنید تا متوجه تفاوت الگوریتمها، کیفیت و مرتبط بودن نتایجشان بشوید.
موتور جستجو تخصصی یکی از انواع موتورهای جستجو است که اطلاعات تخصصی را در زمینه های خاص در اختیار مخاطبین قرار میدهد. مانند:
- موتور جستجو حقوقی
- موتور جستجو خانه
- موتور جستجو خرید کالا
- موتور جستجو شعر
- موتور جستجوی پزشک
- موتور جستجوی خودرو
- موتور جستجو مخصوص فیلم
- موتور جستجوی قرآن
شاید برای شما جالب باشد که تعداد زیادی موتور جستجو ایرانی هم داریم. مانند:
- موتور جستجو ترب
- موتور جستجو جس جو
- موتور جستجو ذره بین
- موتور جستجو ریسمون
- موتور جستجو زومیت
- موتور جستجو فارسی جو
- موتور جستجو گردو
- موتور جستجو یوز
من در اینجا برخی از آنها را معرفی کردم و این به معنای تائید عملکرد آنها نیست و خواستم با موتور جستجوی ایرانی هم آشنا شوید.
خزش: آیا موتورهای جستجو قادر به پیدا کردن صفحات سایت شما هستند؟
همانطور که اشاره شد وجود قابلیت خزش و ایندکس شدن سایت جزء پیش شرطهای لازم برای نمایش سایت در صفحه نتایج موتورهای جستجو است. اگر سایتی دارید کار را با بررسی تعداد صفحات سایت که در ایندکس گوگل قرار دارند شروع کنید که این کار اطلاعات ارزشمندی درباره اینکه آیا گوگل قادر به خزش و پیدا کردن صفحات سایت شما هست یا خیر فراهم میکند.
یکی از روشهای بررسی صفحات ایندکس شده استفاده از site:yourdomain.com است که جزء عملگرهای پیشرفته جستجو است. برای انجام این کار در کادر جستجوی گوگل عبارت site:yourdomain.com را تایپ کنید تا ایندکسهای ایجاد شده توسط گوگل برای سایت مورد نظرتان مشخص شود:
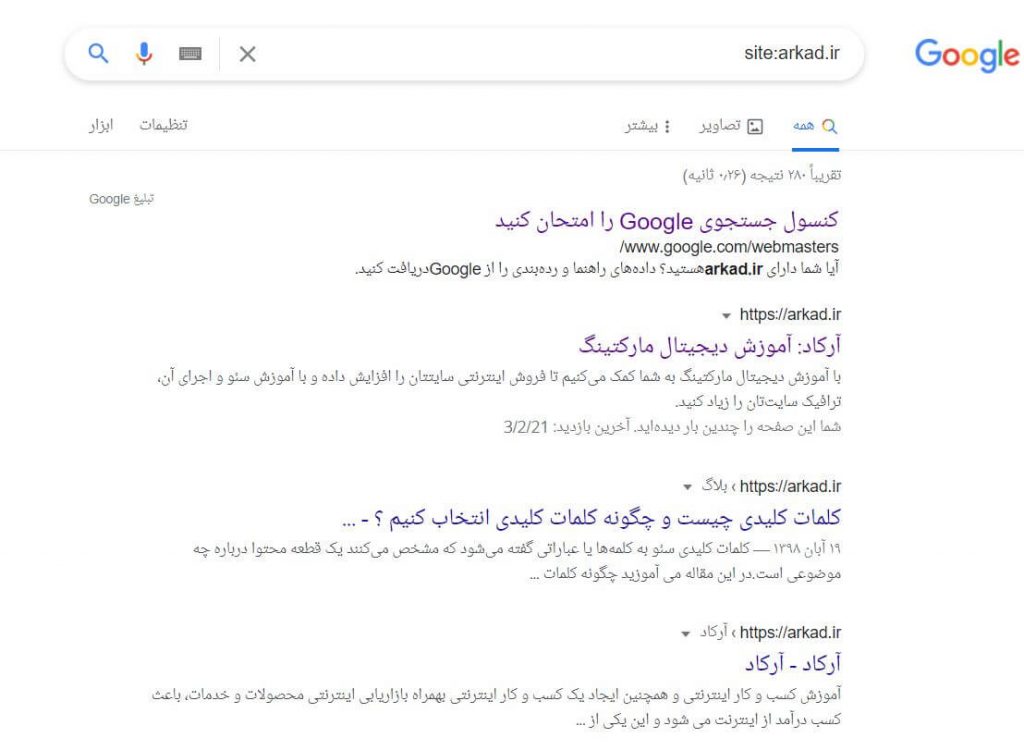
تعداد نتایج ایجاد شده توسط گوگل دقیق نیست (بخش About XX results) اما به شما درباره اینکه چه صفحاتی از سایتتان ایندکس شده و اینکه در حال حاضر چه وضعیتی در نتایج جستجو دارند کمک میکند.
برای دستیابی به نتایج دقیقتر میتوانید از گزارش Index Coverage (یا پوشش ایندکس) در سرچ کنسول استفاده کنید. با این ابزار میتوانید سایت مپ خودتان را ارسال کنید و بررسی کنید که چه تعداد از صفحات سایتتان به ایندکس گوگل اضافه شدهاند.
اگر سایت شما در نتایج موتور جستجو نمایش داده نمیشود، ممکن است این مشکل به دلایل مختلفی ایجاد شده باشد از جمله اینکه:
- سایت شما کاملاً تازه کار است و هنوز مورد خزش قرار نگرفته است.
- هیچ وبسایت خارجی لینک سایت شما را در محتوای خودش درج نکرده است.
- طراحی سایت شما به نحوی است که باعث شده رباتهای خزشگر نتوانند به راحتی آن را پیمایش کنند.
- سایت شما حاوی کدهای خاصی است که مانع دسترسی موتور جستجوگر میشود.
- به دلیل استفاده از تاکتیکهای اسپمی، سایت شما توسط گوگل جریمه شده است.
به گوگل اعلام کنید که سایت شما را چگونه خزش کند
اگر عملگر site:domain.com را برای سایتتان استفاده کرده و متوجه شدید که بعضی از صفحات مهم سایت شما در ایندکس موجود نیستند یا بعضی از صفحات غیرمهم به اشتباه ایندکس شدهاند، میتوانید برای راهنمایی هر چه بیشتر ربات گوگل جهت پویش سایت خودتان از روشهای مختلفی استفاده کنید. اعلام نحوه پویش سایت به موتورهای جستجو امکان کنترل بیشتر بر نحوه ایندکس شدن سایت را فراهم میکند.
اکثر افراد تصور میکنند پیدا شدن صفحات مهم توسط گوگل کفایت میکند اما شاید صفحاتی هم باشند که نخواهید ربات گوگل آنها را پیدا کند مثل لینکهای قدیمی که حالا محتوای ضعیفی دارند، URLهای تکراری (مثل پارامترهای مرتب سازی و فیلتر برای فروشگاههای آنلاین)، صفحات مربوط به یکسری کدهای تبلیغاتی خاص، صفحه تست، صفحه تشکر و غیره.
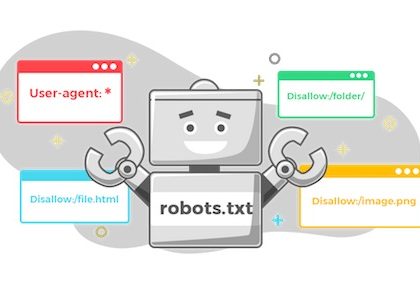
برای راهنمایی ربات گوگل جهت دور ماندن از بعضی بخشهای سایت، از robots.txt استفاده کنید.
فایل Robots.txt
فایل Robots.txt در پوشه روت وبسایتها قرار دارد (مثل yourdomain.com/robots.txt) و نشان میدهد که چه بخشهایی از سایت شما باید توسط موتورهای جستجو خزش شوند یا نشوند و سرعت خزش سایت شما چقدر باشد. با تنظیم این فایل بخشی از سئوی تکنیکال سایت خود را بهینه نمودهاید.
ربات گوگل چطور با فایل robots.txt برخورد میکند؟
- اگر ربات گوگل نتواند فایل robots.txt را برای یک سایت پیدا کند، شروع به خزش سایت میکند.
- اگر ربات گوگل فایل robots.txt را پیدا کند، معمولاً از دستورات آن تبعیت میکند و به همان روش خزش سایت را انجام میدهد.
- اگر ربات گوگل حین دسترسی به فایل robots.txt با خطا روبرو شود و نتواند وجود یا عدم وجود آن را تشخیص دهد، سایت را خزش نمیکند.
بهینه سازی بودجه خزش
بودجه خزش میانگین تعداد URLهایی است که ربات گوگل پیش از ترک سایت شما آنها را پویش میکند بنابراین بهینهسازی بودجه خزش این اطمینان را ایجاد میکند که وقت ربات گوگل برای بررسی صفحات غیرمهم سایت شما تلف نمیشود تا خطر عدم پویش صفحات مهم ایجاد نشود. بودجه خزش برای سایتهای بزرگی با دهها هزار URL اهمیت بیشتری دارد اما بهتر است در هر صورت مانع از دسترسی خزشگرها به محتوایی شوید که برای شما مهم نیست. فقط مطمئن شوید که دسترسی خزشگر را به صفحاتی که دستورالعملهای خاصی برای آنها اضافه کردید مثل تگهای noindex یا Canonical محدود نکنید. اگر دسترسی ربات گوگل به صفحهای محدود شود، امکان مشاهده دستورالعملهای آن صفحه را نخواهد داشت.
لزوماً همه رباتهای وب از robots.txt تبعیت نمیکنند. ممکن است اشخاصی با اهداف و مقاصد نامطلوب (مثل خراش دهندههای[۱] ایمیل آدرس) رباتهایی بسازند که از این پروتکل تبعیت نکنند. در واقع بعضی از افراد بد نیت از فایلهای robots.txt برای پیدا کردن محل درج محتوای حساس استفاده میکنند. هر چند منطقی است که دسترسی خزشگرها به صفحات خصوصی مثل صفحات لاگین و مدیریت سایت را محدود کنید تا در ایندکس نمایش داده نشوند، اما قرار دادن محل این URLها در فایل robots.txt که همه به آن دسترسی دارند باعث میشود که مهاجمان سایبری به راحتی به آن دسترسی پیدا کنند. به جای درج این صفحات در فایل robots.txt، بهتر است آنها را NoIndex کرده و پشت یک صفحه لاگین قرار دهید.
تعریف پارامترهای URL در سرچ کنسول
بعضی از سایتها (بیشتر سایت فروشگاههای آنلاین) با اضافه کردن یکسری پارامتر خاص به URLها، از یک محتوای خاص چندین بار در URLهای مختلف استفاده میکنند. اگر تا به حال خرید آنلاین انجام داده باشید به احتمال زیاد جستجوهای خودتان را با یکسری فیلتر خاص محدود کردهاید. مثلاً وقتی کلمه Shoes (کفش) را در سایت آمازون جستجو میکنید و بعد با انتخاب رنگ، اندازه و سبک، جستجو را محدود میکنید. در این حالت URL سایت کمی تغییر میکند، مثلاً:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/w
women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
اما گوگل چطور تشخیص میدهد که کدام URL را به جستجو کنندهها نمایش دهد؟ واقعیت این است که گوگل به خوبی تشخیص میدهد که کدام URL مناسبتر است اما میتوانید با استفاده از ویژگی URL Parameters در سرچ کنسول به گوگل اعلام کنید که دقیقاً میخواهید چه رفتاری با صفحات شما انجام دهد.
اگر از این قابلیت استفاده کنید تا به گوگل اعلام کنید که «هیچ نشانی با پارامترهای ____ را خزش نکن» در این صورت شما در واقع این محتوا را از ربات گوگل مخفی میکنید در نتیجه این محتوا از نمایش جستجو حذف میشود. برای پارامترهایی که منجر به ایجاد صفحات تکراری میشوند میتوانید از این روش استفاده کنید اما این روش برای صفحاتی که تمایل دارید ایندکس شوند مناسب نیست.
آیا خزشگرها قادر به یافتن همه مطالب مهم هستند؟
حالا که با بعضی تاکتیکهای پیشگیری از خزش صفحات غیرمهم آشنا شدید، به بهینه سازیهایی میپردازیم که به ربات گوگل برای پیدا کردن صفحات مهم کمک میکنند.
گاهی اوقات موتور جستجو میتواند بخشهایی از سایت شما را با خزش کردن پیدا کند اما ممکن است بعضی دیگر از صفحات یا بخشها به دلایل خاصی مبهم باشند. پس باید اطمینان حاصل کنید که موتورهای جستجو قادر به تشخیص همه محتوایی که تمایل دارید ایندکس شود باشند نه فقط صفحه اصلی سایت.
پس از خودتان بپرسید که آیا ربات خزشگر میتواند کل سایت شما را به خوبی پویش کند؟
آیا محتوای سایت پشت فرمهای لاگین پنهان شده است؟
اگر قرار است کاربران برای دسترسی به بعضی مطالب خاص وارد سایت شده، فرمی پر کرده یا به نظرسنجی پاسخ دهند موتورهای جستجو هم قادر به مشاهده این صفحات نخواهند بود چون قطعاً خزشگر گوگل قادر به لاگین کردن نیست.
آیا به فرمهای جستجو متکی هستید؟
رباتها قادر به استفاده از فرمهای جستجو نیستند. بعضیها تصور میکنند که اگر یک کادر جستجو در سایتشان قرار دهند موتورهای جستجو میتوانند هر آنچه کاربران جستجو میکنند را پیدا کنند.
آیا متنها بین محتوای غیرمتنی مخفی شدهاند؟
نباید از فرمهای غیرمتنی (عکس، ویدیو، گیف و غیره) برای نمایش متنی استفاده کنید که میخواهید ایندکس شود. هر چند قدرت موتورهای جستجو برای تشخیص تصاویر بیشتر شده اما هنوز تضمینی وجود ندارد که قادر به خواندن و درک تصاویر باشند. بهتر است متون را در مارکاپ <HTML> صفحه درج کنید.
آیا موتورهای جستجو میتوانند سایت شما را پیمایش کنند؟
درست همانطور که خزشگر باید سایت شما را از طریق لینکهای درج شده در سایتهای دیگر پیدا کند، برای حرکت از صفحهای به صفحه دیگر هم نیاز به مسیری متشکل از لینکهای مختلف دارد. اگر صفحهای که مایل به ایندکس شدن آن هستید، هیچ لینکی از صفحات دیگر دریافت نکرده باشد، ربات گوگل قادر به مشاهده آن نیست. طراحان خیلی از سایتها دچار این اشتباه میشوند که سایت را طوری سازماندهی میکنند که موتورهای جستجو قادر به دسترسی به همه صفحات آن نیستند در نتیجه امکان درج سایت در نتایج جستجو وجود ندارد.
اشتباهات متداولی که مانع از دسترسی خزشگرها به کل سایت میشوند:
- ایجاد نتایج متفاوت هنگام پیمایش سایت با موبایل و با کامپیوتر.
- هر گونه پیمایشی که در آن آیتمهای منو در HTML وجود ندارد مثل پیمایش با جاوااسکریپت. گوگل قابلیتهای بیشتری برای درک و خزش جاوااسکریپت پیدا کرده اما هنوز به مرحله تکامل نرسیده است. مطمئنترین راه برای پیدا شدن، درک و ایندکس شدن صفحات سایت توسط گوگل، استفاده از HTML است.
- شخصی سازی یا نمایش روش پیمایش یا مرور خاص برای بعضی از بازدیدکنندگان که ممکن است باعث مخفی شدن محتوا از دید خزشگر شود.
- فراموش کردن درج لینک صفحات مهم سایت برای ایجاد یک مسیر پیمایش کامل – به خاطر داشته باشید که لینکها، مسیرهایی هستند که خزشگرها برای پیدا کردن صفحات جدید از آنها استفاده میکنند.
به همین علت سایت شما باید یک مسیر پیمایش واضح و ساختاری منظم داشته باشد.
آیا یک معماری اطلاعاتی تمیز و مرتب دارید؟
معماری اطلاعاتی به سازماندهی و برچسب گذاری محتوای سایت برای ارتقای بهرهوری و امکان پیدا شدن آن توسط کاربران گفته میشود. یک معماری اطلاعاتی خوب شهودی و قابل درک است یعنی برای بررسی سایت جهت پیدا کردن یک آیتم خاص نیازی به گشتن و جستجوی بسیار زیاد سایت وجود ندارد.
آیا از سایت مپ استفاده میکنید؟
در مجموع سایت مپ (Sitemap) یک فهرست از URLهای سایت است که خزشگرها میتوانند از آن برای پیدا کردن و ایندکس کردن محتوای سایت استفاده کنند. یکی از ساده ترین راهها برای اطمینان از اینکه گوگل صفحاتی با بیشترین سطح اولویت را پیدا میکند ساختن فایلی است که با استانداردهای گوگل همخوانی دارد و سپس، ارسال کردن آن به سرچ کنسول. هرچند ارسال سایت مپ نمیتواند جایگزین امکان مرور سایت به روشی واضح و شفاف شود اما قطعاً میتواند به خزشگرهای گوگل برای پیدا کردن مسیر همه صفحات مهم سایت کمک کند.
سعی کنید فقط URLهایی را درج کنید که میخواهید موتورهای جستجو آنها را ایندکس کنند و حتماً مسیرهایی منسجم و درست در اختیار خزشگرها قرار دهید. مثلاً اگر URL خاصی را در robots.txt مسدود کردهاید آن را در سایت مپ درج نکنید یا URLهایی را درج نکنید که تکراری هستند و به جای آن نسخه کانونی اصلی (Canonical) را درج کنید.
اگر سایت شما هیچ لینکی از سمت سایتهای دیگر ندارد، باز هم شاید بتوانید با ارسال سایت مپ XML آن به سرچ کنسول آن را ایندکس کنید. تضمینی وجود ندارد که گوگل URL ارسال شده را در ایندکس خودش درج کند اما قطعاً این کار ارزش امتحان کردن را دارد.
آیا خزشگرها برای دسترسی به URLهای شما با خطا روبرو میشوند؟
ممکن است خزشگر در فرایند خزش URLهای سایت با خطا روبرو شود. میتوانید برای تشخیص URLهایی که چنین خطایی برای آنها ایجاد شده به گزارش Crawl Errors از سرچ کنسول مراجعه کنید – این گزارش خطاهای سرور و خطاهای پیدا نشدن محتوا را نشان میدهد. فایلهای لاگ سرور هم این موضوع و مجموعهای از اطلاعات جامع درباره بازههای اجرای فرایند خزش را در اختیار شما قرار میدهند اما از آنجایی که دسترسی به فایلهای لاگ سرور و تحلیل آنها یک موضوع پیشرفته است در این مقاله به طور کامل آن را بررسی نمیکنیم.
پس لازم است پیش از هر چیزی مفهوم خطاهای سرور و خطاهای “پیدا نشد” (not found) را درک کنید.
کدهای ۴xx: وقتی خزشگرهای موتور جستجو به دلیل بروز خطای کلاینت قادر به دسترسی به محتوا نیستند.
خطاهای ۴xx خطای کلاینت هستند یعنی URL درخواستی حاوی غلطهای ساختاری است یا امکان اجرای آن وجود ندارد. یکی از متداول ترین خطاهای ۴xx، خطای “۴۰۴ – not found”است. برای مثال ممکن است این خطا به دلیل اشتباه تایپی، حذف شدن صفحه یا ایجاد مشکل در فرایند هدایت (redirect) به سمت یک URL دیگر رخ داده باشد. وقتی موتورهای جستجو با خطای ۴۰۴ روبرو میشوند قادر به دسترسی به URL نیستند. وقتی کاربران با خطای ۴۰۴ روبرو میشوند خسته شده و سایت را ترک میکنند.
کدهای ۵xx: وقتی خزشگرهای موتور جستجو به دلیل بروز خطای سرور قادر به دسترسی به محتوا نیستند.
خطاهای ۵xx خطای سرور هستند یعنی سروری که صفحه وب مورد نظر روی آن قرار گرفته قادر به برآورده کردن درخواست جستجو کننده یا موتور جستجو برای دسترسی به صفحه مورد نظر نیست. در گزارش Crawl Error سرچ کنسول یک تب اختصاصی برای این خطاها وجود دارد. معمولاً این خطاها به این دلیل رخ میدهند که مدت زمان سپری شده برای درخواست URL مورد نظر از آستانه مجاز فراتر رفته در نتیجه ربات گوگل این درخواست را رها میکند. برای کسب اطلاعات بیشتر جهت رفع مشکلات اتصال سرور، میتوانید به مدارک گوگل مراجعه کنید.
خوشبختانه یک روش خاص برای اعلام جابجا شدن صفحه مورد نظر به موتور جستجو و کاربران وجود دارد یعنی ریدایرکت (دائم) ۳۰۱٫
ساختن صفحات ۴۰۴ سفارشی
میتوانید با درج لینک صفحات مهم سایت، یکی از امکانات جستجوی سایت و حتی اطلاعات تماس صفحه ۴۰۴ را سفارشی سازی کنید. به این ترتیب احتمال اینکه کاربران پس از برخورد به خطای ۴۰۴ سایت شما را ترک کنند کاهش پیدا میکند.
ریدایرکت ۳۰۱
فرض کنید صفحهای را از example.com/young-dogs/ به example.com/puppies/ منتقل میکنید. موتورهای جستجو و کاربران برای حرکت از URL قدیمی به جدید نیاز به یک پل دارند و این پل ریدایرکت ۳۰۱ است.
| چه موقع ۳۰۱ را پیاده سازی کنید | چه موقع ۳۰۱ را پیاده سازی نکنید | |
| ارزش (برابری) لینک | انتقال ارزش لینک از محل قدیمی صفحه به URL جدید | بدون ۳۰۱، اعتبار و ارزش از URL قبلی به نسخه جدید URL منتقل نمیشود |
| ایندکسینگ | به گوگل برای پیدا کردن و ایندکس کردن نسخه جدید صفحه کمک میکند. | وجود خطای ۴۰۴ در سایت شما به تنهایی آسیبی به عملکرد سایت در موتور جستجو وارد نمیکند اما وجود خطای ۴۰۴ برای صفحاتی با رتبه یا ترافیک زیاد میتواند باعث حذف آنها از ایندکس شده در نتیجه ترافیک و رتبهها هم با ایندکس از بین میروند. |
| تجربیات کاربری | مطمئن شوید که کاربران صفحهای که در جستجوی آن هستند را پیدا میکنند. | اگر به کاربران اجازه دهید روی لینکهای مرده کلیک کنند باعث هدایت آنها به سمت صفحات خطادار میشوید که تجربه خوبی نیست. |
کد وضعیت ۳۰۱ یعنی صفحه برای همیشه به یک محل جدید منتقل شده پس از ریدایرکت کردن URLها به سمت صفحاتی نامربوط خودداری کنید – یعنی URLهایی که دیگر محتوای URL قدیمی در آنها قرار ندارد. اگر صفحه برای یک کوئری خاص رتبه گرفته و آن را با ۳۰۱ به صفحه یک URL با محتوایی متفاوت هدایت کنید ممکن است رتبه صفحه ریزش کند چون محتوایی که باعث شده بود این URL برای کوئری مورد نظر مناسب باشد دیگر در آنجا نیست. ۳۰۱ ابزار قدرتمندی است – URLها را با دقت و مسئولیت پذیری جابجا کنید.
امکان ریدایرکت کردن ۳۰۲ را هم دارید اما باید این کد را برای جابجاییهای موقت و وقتی بحث ارزش لینک (link equity) دغدغه چندانی محسوب نمیشود انجام دهید. ۳۰۲ها به نوعی شبیه به انحراف جاده محسوب میشوند. در واقع شما به صورت موقت ترافیک را به یک مسیر خاص هدایت میکنید اما نباید این کار همیشگی باشد.
مراقب زنجیرههای ریدایرکت باشید!
اگر قرار باشد گوگل بات از طریق چندین ریدایرکت به صفحات شما دسترسی پیدا کند، کار این ربات سختتر میشود. گوگل به این وضعیت زنجیره ریدایرکت میگوید و توصیه میکند تا حد امکان این زنجیرهها را محدود کنید. اگر example.com/1 را به example.com/2 منتقل کنید و بعد تصمیم بگیرید که آن را به example.com/3 منتقل کنید بهتر است حلقه واسط را حذف کرده و فقط example.com/1 را به example.com/3 هدایت کنید.
وقتی مطمئن شدید که سایت شما برای خزش بهینه سازی شده، کار بعدی اطمینان از قابل ایندکس بودن آن است.
ایندکسینگ: موتورهای جستجو صفحات شما را چگونه تفسیر و ذخیره میکنند؟
وقتی مطمئن شدید که سایتتان توسط موتور جستجو خزش شده، مرحله بعد اطمینان از قابل ایندکس بودن آن است. اینکه موتور جستجویی سایت شما را پیدا و خزش کرده لزوماً به این معنا نیست که سایت شما در ایندکس آن موتور جستجو ذخیره میشود. در بخش قبلی که درباره خزش صحبت کردیم، توضیح دادیم که موتورهای جستجو چگونه صفحات وب را پیدا میکنند. ایندکس، جایی است که صفحات پیدا شده در آن ذخیره میشود. بعد از اینکه خزشگر صفحهای را پیدا کرد، موتور جستجو آن را مثل یک مرورگر تحلیل میکند. در این فرایند موتور جستجو محتوای صفحه را تحلیل کرده و همه اطلاعات پیدا شده را در ایندکسش ذخیره میکند.

در ادامه به شما خواهیم گفت که ایندکسینگ چگونه کار میکند و چطور میتوانید مطمئن شوید که سایت شما هم وارد این دیتابیس مهم میشود.
آیا میتوانیم نحوه مشاهده صفحات سایت توسط خزشگر گوگل بات را مشاهده کنیم؟
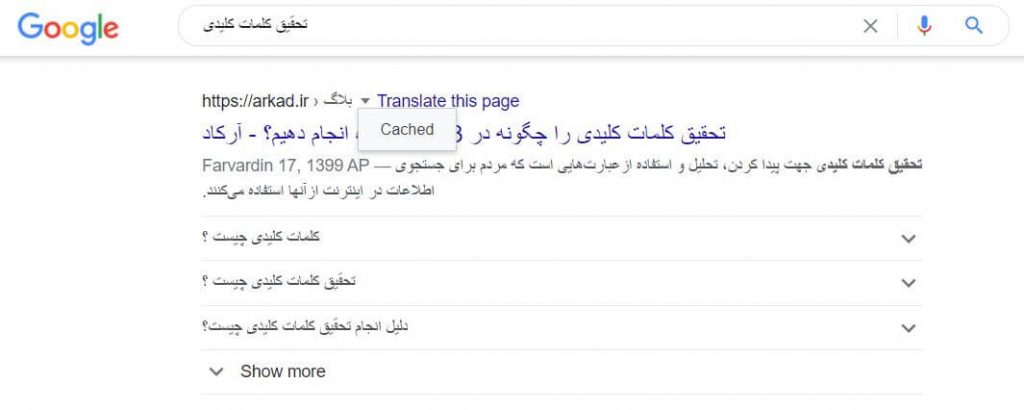
بله، نسخه کش شده صفحات سایت شما نشان دهنده یک اسنپ شات از آخرین باری است که گوگل بات آن را خزش کرده است.
گوگل در بازههای زمانی مختلف صفحات وب را خزش و ایندکس میکند. وبسایتهای مهم و شناخته شده که دائماً مطلب منتشر میکنند مثل https://www.nytimes.com نسبت به سایتهای کمتر شناخته شده در فواصلی کوتاهتر خزش میشوند. میتوانید با کلیک کردن روی فلش کنار URL در نتایج جستجو و انتخاب گزینه Cached نسخه کش شده سایتتان را مشاهده کنید:
میتوانید نسخه فقط متنی سایتتان را هم مشاهده کنید تا از خزش و کش شدن محتوای مهم سایتتان مطمئن شوید.
آیا صفحات از ایندکس حذف میشوند؟
قطعاً بله! امکان حذف صفحات از ایندکس به این دلایل وجود دارد:
- URL مورد نظر خطای not found (4XX)یا خطای سرور (۵XX) ایجاد میکند. ممکن است این خطا تصادفی باشد (صفحه جابجا شده و ریدایرکت ۳۰۱ تنظیم نشده) یا عمدی (صفحه حذف شده و برای حذف از ایندکس دچار خطای ۴۰۴ شده است).
- به URL مورد نظر تگ متای noindex اضافه شده – مالک سایت میتواند این تگ را اضافه کند تا به موتور جستجو اعلام کند صفحه را از ایندکسش حذف کند.
- URL مورد نظر به دلیل نقض قوانین وب مستر موتور جستجو با جریمه دسترسی روبرو شده در نتیجه از ایندکس حذف شده است.
- اضافه شدن پسورد برای دسترسی به صفحه مورد نظر باعث شده که امکان خزش URL مورد نظر وجود نداشته باشد.
اگر معتقد هستید که یکی از صفحات سایت شما قبلاً در ایندکس گوگل بوده و حالا جایی در آن ندارد، میتوانید از ابزار URL Inspection برای کسب اطلاعات بیشتر درباره آن صفحه استفاده کنید یا از Fetch as Google استفاده کنید که یک قابلیت به اسم Request Indexing دارد که میتوان URLهای دلخواه را برای ایندکس شدن به آن ارسال کرد (ابزار fetch سرچ کنسول هم گزینهای به اسم render دارد که با استفاده از آن میتوانید مشکلات احتمالی به وجود آمده برای گوگل در تحلیل صفحه را بررسی کنید).
به موتورهای جستجو اعلام کنید که صفحات سایتتان را چگونه ایندکس کنند
دستورات متای رباتها
دستورات متا (یا تگهای متا) راهنماییها و دستوراتی هستند که شما در رابطه با نحوه برخورد موتور جستجو با صفحات سایتتان به موتورهای جستجو میدهید.
میتوانید به موتورهای جستجو اعلام کنید که “این صفحه را در نتایج جستجو ایندکس نکن” یا “هیچ ارزش لینکی را به هیچ لینک درون صفحهای ارسال نکن”. این دستورات از طریق Robots Meta Tags در بخش <head> از صفحه HTML اجرا میشوند (که روش پرکاربردتر است) یا از طریق X-Robots-Tag در هدر HTTP.
تگ متای Robots
میتوانید از تگ متای robots در بخش <head> از صفحه HTML سایتتان استفاده کنید. این تگ میتواند همه یا بعضی از موتورهای جستجوی دلخواه را استثناء کند. در ادامه متداول ترین دستورات متا را همراه با شرایط استفاده از آنها مشاهده میکنید.
index/noindex به موتور جستجو اعلام میکند که آیا صفحه مورد نظر باید خزش شده و در ایندکس موتور جستجو حفظ شود یا خیر. اگر از noindex استفاده کنید در واقع به خزشگرها اعلام میکنید که میخواهید صفحه مورد نظر در نتایج جستجو قرار نداشته باشد. موتورهای جستجو در حالت پیش فرض تصور میکنند که میتوانند همه صفحات را ایندکس کنند پس استفاده از مقدار index ضرورتی ندارد.
- چه موقع از این صفت استفاده میکنیم؟ اگر به هر دلیلی بخواهید صفحهای را از ایندکس گوگل حذف کنید (مثلاً صفحات پروفایل ساخته شده توسط کاربران) اما باز هم بخواهید که بازدیدکنندگان به آن دسترسی داشته باشند از noindex استفاده میکنید.
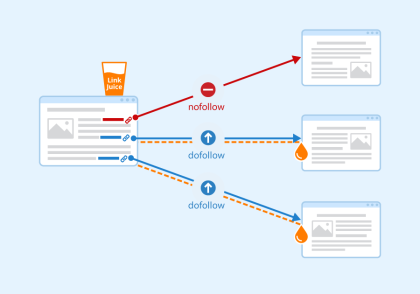
follow/nofollow به موتورهای جستجو اعلام میکند که آیا باید لینکهای درون یک صفحه خاص را دنبال کنند یا خیر. Follow باعث میشود که رباتها لینکهای درج شده در صفحات را دنبال کرده و ارزش لینکها را از طریق URLها منتقل کنند یا میتوانید از حالت nofollow استفاده کنید تا موتور جستجو لینکها را دنبال نکرده و ارزش لینک را منتقل نکند. همه موتورهای جستجو در حالت پیش فرض صفت follow را در نظر میگیرند.
- چه موقع از این صفت استفاده میکنیم؟ معمولاً از nofollow همراه noindex و در مواقعی استفاده میکنیم که بخواهیم مانع از ایندکس شدن یک صفحه و مانع از دنبال کردن لینکهای آن صفحه توسط خزشگرها شویم.
Noarchive برای پیشگیری از ذخیره کردن نسخه کش شده صفحه توسط موتورهای جستجو استفاده میشود. در حالت پیش فرض موتورهای جستجو نسخهای از همه صفحات ایندکس شده ذخیره میکنند که از طریق لینک مربوط به محتوای کش شده در نتایج جستجو، در دسترس جستجوکنندهها قرار میگیرد.
- چه موقع از این صفت استفاده میکنیم؟ اگر یک فروشگاه آنلاین دارید و قیمت محصولات شما دائماً تغییر میکند، سعی کنید برای پیشگیری از مشاهده قیمتهای قدیمیتوسط کاربران موتورهای جستجو از تگ noarchive استفاده کنید.
در ادامه یک نمونه از تگ noindex, nofollow را مشاهده میکنید:
<!DOCTYPE html><html><head><meta name="robots" content="noindex, nofollow" /></head><body>...</body></html>
این مثال باعث میشود که همه موتورهای جستجو از ایندکس کردن صفحه و دنبال کردن لینکهای درون آن خودداری کنند. اگر میخواهید فقط چند خزشگر مثل ربات گوگل و بینگ را از انجام این کار منع کنید میتوانید از چند تگ مشابه استفاده کنید که هر کدام برای یکی از موتورهای جستجوی مورد نظر نوشته شده باشد.
X-Robots-Tag
تگ x-robots در هدر HTTP از URL استفاده میشود و نسبت به تگهای متا برای مسدود کردن وسیع موتورهای جستجو مناسبتر است چون میتوانید در این تگ از عبارات باقاعده استفاده کنید، فایلهای غیر HTML را مسدود کنید و تگ noindex در سطح سایت داشته باشید.
مثلاً میتوانید به راحتی همه انواع فایل یا پوشههای مورد نظر را از فهرست ایندکس خارج کنید (مثلاً moz.com/no-bake/old-recipes-to-noindex)
<Files ~ “\/?no\-bake\/.*”> Header set X-Robots-Tag “noindex, nofollow”</Files>
میتوان از دستورات استفاده شده در تگ متای robots در X-Robots-Tag هم استفاده کرد.
یا انواع فایل خاصی را مشخص کرد (مثل پی دی اف):
<Files ~ “\.pdf$”> Header set X-Robots-Tag “noindex, nofollow”</Files>
یک نکته برای وردپرس:
در بخش Dashboard> Settings> Reading چک کنید که گزینه “Search Engine Visibility” تیک نخورده باشد چون این تنظیمات مانع از ورود موتورهای جستجو به سایت شما از طریق فایل robots.txt میشود.
درک روشهای تأثیرگذاری بر خزش و ایندکس سایت به شما برای پیشگیری از انجام اشتباهات متداولی که مانع از پیدا شدن صفحات مهم میشوند کمک میکند.
رتبه بندی: موتورهای جستجو چگونه به URLها رتبه میدهند؟
موتورهای جستجو چطور اطمینان حاصل میکنند که وقتی یک کوئری در نوار جستجو درج میکنید، یک نتیجه مرتبط به شما نمایش میدهند؟ این کار با فرایند رتبهبندی یا مرتب کردن نتایج جستجو بر حسب مرتبطترین تا کم ربطترین نتایج انجام میشود.

آنها برای تعیین میزان تناسب و ارتباط محتوا، از فرمول یا فرایندی استفاده میکنند که با استفاده از آن اطلاعات مرتب شده بازیابی شده و به روشی معنادار مرتب میشود. این الگوریتمها در سالهای اخیر تغییرات زیادی کردهاند تا کیفیت نتایج را ارتقاء دهند. مثلاً گوگل هر روز الگوریتمهای خودش را تغییر میدهد – بعضی از آپدیتها جزئی و بعضی مهم و گستردهتر هستند و برای رفع مشکلی خاص طراحی میشوند مثل الگوریتم پنگوئن برای برخورد با لینک های اسپم.
اما چرا این الگوریتمها اینقدر تغییر میکنند؟ هر چند خود گوگل توضیحات خاصی درباره دلیل انجام این تغییرات ارائه نکرده اما در جریان هستیم که هدف کلی گوگل ارتقای کیفیت جستجو است. به همین دلیل گوگل هم در پاسخ به پرسشهای مطرح شده درباره این تغییرات معمولاً میگوید: “ما همیشه در حال انتشار آپدیتهای کیفی هستیم.” این نشان میدهد که اگر پس از انتشار یک الگوریتم خاص سایت شما متضرر شده، میتوانید دستورالعملهای کیفی گوگل یا دستورالعملهای کیفی رتبه بندی گوگل را بررسی کنید که هر دو اطلاعات خیلی خوبی درباره خواستهها و انتظارات این موتور جستجو در اختیار شما قرار میدهند.
موتورهای جستجو چه خواستهای دارند؟
خواسته موتورهای جستجو همیشه یک چیز بوده: ارائه پاسخ مفید برای سوالات جستجوکنندهها در فرمتهای مفیدتر. اگر این موضوع صحت دارد چرا امروزه حوزه سئو نسبت به چند سال پیش تغییر یافته است؟
میتوان این بحث را مثل یادگرفتن یک زبان جدید دانست.
اول، درک زبان آموز از زبان مورد نظر بسیار محدود است اما به مرور زمان درک او عمیقتر شده و مفاهیم را یاد میگیرد – یعنی معنای پشت زبان و روابط بین کلمات و عبارات. در نهایت با تمرین کافی، زبان آموز به مرحلهای میرسد که میتواند ظرافتها را درک کند و حتی به سوالات مبهم یا ناقص هم پاسخ دهد.
وقتی موتورهای جستجو تازه یاد گرفتن زبان ما رو شروع کرده بودند، بازی دادن این سیستمها با استفاده از ترفندها و تاکتیکهایی بر خلاف دستورالعملهای کیفی این موتورها کار آسانی بود. مثلاً با استفاده از روش پرکردن محتوا از کلمات کلیدی. در آن دوره اگر میخواستید برای کلمه کلیدی مثل “لطیفههای خنده دار” رتبه بگیرید، این کلمه کلیدی را چندین بار به محتوای صفحه اضافه کرده و برجسته میکردید به این امید که رتبه خودتان برای آن کلمه کلیدی را ارتقاء دهید:
به سایت لطیفههای خندهدار خوش آمدید! ما خندهدارترین لطیفههای دنیا را داریم. این لطیفههای خندهدار بامزه و جالب هستند. لطیفههای خندهدار منتظر شما هستند. این لطیفههای خندهدار را بخوانید چون لطیفههای خندهدار شما را شاد و سرگرم میکنند….
چنین تاکتیکی تجربیات کاربری را به شدت تنزل میداد و کاربران به جای خواندن لطیفههای خندهدار با متنی روبرو میشدند که آنها را عصبانی میکرد و خواندنش سخت بود. شاید قدیم چنین روشی کار میکرد اما این چیزی نبود که موتورهای جستجو واقعاً به دنبال آن باشند.
نقش لینکها در سئو
وقتی درباره لینک صحبت میکنیم در مجموع دو نوع لینک در نظر داریم. (۱) بک لینک یا لینک جاذبهای یعنی لینکهایی که از سمت سایر سایتها به سایت شما ایجاد میشوند و (۲) لینکهای داخلی در سایت خود شما که صفحهای را به صفحه دیگر لینک میکنند (در همان سایت).

لینکها همیشه در سئوی داخلی و سئوی خارجی نقش مهمی داشتهاند. در اولین روزهای سئو، موتورهای جستجو برای تشخیص URLهای قابل اعتمادتر نیاز به کمک داشتند تا نتایج جستجو را به بهترین شکل ممکن رتبه بندی کنند. محاسبه تعداد لینکهایی که به یک سایت خاص اشاره دارند، به آنها برای رسیدن به این هدف کمک میکرد.
بک لینکها شباهت زیادی به تبلیغات دهان به دهان دارند. برای مثال یک کافی شاپ را در نظر بگیرید. مثلاً قهوه جِنی (Jenny’s Coffee)
- تبلیغ و توصیه کافی شاپ توسط دیگران = نشانهای از معتبر بودن
- مثال: خیلی از مردم اعلام کردند که کافی شاپ جنی بهترین کافی شاپ شهر است.
- تبلیغ و توصیه توسط خود شما = جانب گرایانه است و نشانه چندان خوبی نیست
- مثال: جنی ادعا میکند که قهوه جنی بهترین قهوه در شهر است
- تبلیغ و توصیه از سمت منابع بی ربط یا کم کیفیت = نشانه چندان خوبی نیست و حتی ممکن است نوعی اسپم تلقی شود.
- مثال: جنی به اشخاصی که هیچ وقت به کافی شاپ او نرفتهاند پول داده تا از کافی شاپش تعریف کنند.
- عدم وجود تبلیغ و توصیه = نامشخص بودن میزان اعتبار
- مثال: شاید قهوه جنی خوب باشد اما نمیتوان جایی درباره آن نظری پیدا کرد پس نمیتوان نسبت به آن مطمئن بود.
به همین دلیل بود که PageRank شکل گرفت. PageRank (بخشی از الگوریتم اصلی گوگل) یک الگوریتم تحلیل لینک است که نام آن برگرفته از نام یکی از بنیانگذاران گوگل به نام Larry Page است. PageRank اهمیت صفحه را با ارزیابی کیفیت و کمیت لینکهایی که به آن اشاره دارند ارزیابی میکند. فرض بر این است که هر چقدر صفحهای متناسبتر، مهمتر و قابل اعتمادتر باشد، لینکهای بیشتری به دست میآورد.
هر چقدر لینکهای طبیعیتری از وبسایتهایی با اقتدار بالا (قابل اعتماد) به دست آورید، شانس شما برای کسب رتبههای بالاتر در نتایج جستجو بیشتر میشود.
نقش محتوا در سئو
اگر لینکها کاربران را به سمت هیچ محتوایی هدایت نکنند، وجودشان بی فایده است. البته محتوا بسیار فراتر از کلمات است و هر چیزی را شامل میشود که جستجو کنندهها بتوانند از آن استفاده کنند – مثل محتوای ویدیویی، عکس و البته متن. اگر موتورهای جستجو ماشین پاسخ به سوالات باشند، محتوا ابزاری است که با استفاده از آن موتورهای جستجو پاسخ را ارائه میکنند.
هر زمان شخصی جستجویی انجام میدهد، هزاران نتیجه ممکن برای او وجود دارد اما موتورهای جستجو چطور میتوانند تشخیص دهند که چه صفحهای برای مخاطب مورد نظر ارزشمندتر است؟ یکی از عوامل مهم در پاسخ دادن به این سوال، میزان تطبیق محتوای صفحه با قصد کاربر از جستجو است. به عبارت دیگر آیا این صفحات با کلماتی که جستجو شدهاند تطبیق دارند و به جستجوگر برای دستیابی به هدفش کمک میکنند؟
به خاطر همین تمرکز بر رضایت کاربران و انجام کار مورد نظر، هیچ شاخص دقیقی درباره اینکه طول محتوا باید چقدر باشد، چند بار باید کلمه کلیدی در آن درج شود یا چه کلماتی را باید در تگهای هدر درج کنید وجود ندارد. همه این عوامل میتوانند بر عملکرد صفحه در نتایج جستجو تأثیرگذار باشند اما باید تمرکز اصلی کاربرانی باشند که محتوا را مطالعه میکنند.
امروزه با وجود صدها یا حتی هزاران سیگنال رتبه بندی، سه سیگنال مهم همچنان ثابت است یعنی: لینکهای ایجاد شده به سایت شما (که به نوعی مثل نشانه معتبر بودن سایت شما عمل میکنند)، محتوای درون صفحه (محتوای باکیفیتی که با هدف جستجوگر تطبیق داشته باشد) و RankBrain.
RankBrain چیست؟
رنک برین (RankBrain) یکی از اجزای مبتنی بر یادگیری ماشینی در الگوریتم اصلی گوگل است. یادگیری ماشینی نوعی نرمافزار است که به مرور زمان و با بررسی مشاهدات و دادههای آموزشی پیش بینیهای خودش را ارتقاء میدهد. به عبارت دیگر چنین الگوریتمی همیشه در حال یادگیری است و به همین دلیل نتایج ایجاد شده توسط آن هم دائماً باید رو به بهبود باشد.
مثلاً اگر RankBrain متوجه شد که یک URL با رتبه پایینتر نسبت به URL با رتبه بالاتر نتیجه بهتری ایجاد میکند، به احتمال بسیار زیاد ترتیب نتایج را تغییر میدهد تا نتایج مرتبطتر صعود کرده و بالاتر از صفحاتی با نتایج غیرمرتبط قرار بگیرد.

همچون بیشتر موارد مرتبط با موتورهای جستجو، درباره RankBrain هم اطلاعات دقیقی در دست نیست حتی خود کارمندان گوگل هم کاملاً از این موضوع مطلع نیستند.
این موضوع چه پیامدهایی برای سئو دارد؟
از آنجایی که گوگل از RankBrain برای ترویج و تبلیغ محتوای مرتبطتر و مفیدتر استفاده میکند، پس ما هم باید بیشتر از همیشه سعی کنیم نیاز و خواسته جستجوکنندهها را رفع کنیم. پس سعی کنید بهترین اطلاعات و تجربه ممکن را در اختیار جستجوکنندههایی قرار دهید که ممکن است وارد سایت شما شوند و کارهای لازم برای ارتقای عملکرد خودتان در دنیای RankBrain را انجام دهید.
معیارهای تعامل: همبستگی، علیت یا هر دو؟
به احتمال زیاد معیارهای تعامل در رتبه بندیهای گوگل ترکیبی از همبستگی و علیت هستند.
منظور از معیارهای تعامل دادههایی است که نشان میدهند جستجوگرها چطور با سایت شما در نتایج جستجو تعامل برقرار میکنند و این معیارها عبارتند از:
- کلیک (بازدیدهای انجام شده از طریق جستجو)
- زمان سپری شده در صفحه (میزان زمانی که بازدیدکننده قبل از ترک سایت در یک صفحه سپری کرده است)
- نرخ دفع (درصد همه سشنهایی از سایت که در آنها کاربران فقط یک صفحه را مشاهده کردهاند)
- پوگو استیکینگ (Pogo-sticking) (کلیک روی یکی از نتایج جستجو و بعد برگشت سریع به صفحه نتایج جستجو برای انتخاب یک نتیجه دیگر)
خیلی از آزمایشها از جمله “نظرسنجی عوامل رتبه بندی سایت Moz” نشان دادهاند که معیارهای تعامل با رتبه بالاتر تعامل دارند اما بحث علیت به میزان زیادی مورد تردید است. آیا خوب بودن وضعیت معیارهای تعامل جزء ویژگیهای سایتهایی با رتبه بالا است یا این سایتها به دلیل خوب بودن وضعیت معیارهای رتبهبندیشان رتبه بالایی کسب کردهاند؟
نظر موتور جستجو گوگل چیست؟
هر چند گوگل هیچ وقت از اصطلاح “سیگنال مستقیم رتبه بندی” استفاده نکرده اما بدون شک جهت اصلاح نتایج جستجو برای نتایجی خاص، از اطلاعات مربوط به کلیکهای کاربران استفاده میکند.
به گفته Udi Manber مدیر قبلی کیفیت جستجوی گوگل:
“خود رتبه بندی هم تحت تأثیر اطلاعات کلیک قرار دارد. اگر متوجه شویم که برای یک کوئری خاص ۸۰ درصد اشخاص روی نتیجه دوم کلیک کرده و فقط ۱۰ درصد روی اولین نتیجه کلیک میکنند، پس از مدتی متوجه میشویم که به احتمال زیاد نتیجه دوم چیزی است که مردم به دنبال آن هستند پس نتایج را جابجا میکنیم.”
نظر دیگری از Edmond Lau مهندس قبلی شرکت گوگل:
“واضح است که هر موتور جستجوی مسئولیت پذیری از اطلاعات مربوط به کلیکهای روی جستجو برای ارتقای هر چه بیشتر رتبهها و بهبود کیفیت نتایج جستجو استفاده میکند. طرز استفاده دقیق از اطلاعات مربوط به کلیک مشخص نیست اما گوگل اعلام کرده که از اطلاعات مربوط به کلیکهای کاربران برای سیستمهایی مثل رتبه بندی نتایج جستجو استفاده میکند.”
از آنجایی که گوگل باید کیفیت جستجو را حفظ کرده و ارتقاء دهد بدیهی است که معیارهای تعامل فراتر از همبستگی هستند اما ظاهراً به این دلیل گوگل معیارهای رتبه بندی را یک “سیگنال رتبه بندی” نمینامد که از این معیارها برای ارتقای کیفیت جستجو استفاده شده و رتبه URLها صرفاً یک محصول جانبی از این رویکرد است.
چه تستهایی تأیید شدهاند؟
تستهای مختلف نشان دادهاند که گوگل در واکنش به تعامل جستجوگرها، نتایج جستجو را تنظیم میکند:
- آزمون سال ۲۰۱۴ Rand Fishkin باعث شد نتیجه هفتم صفحه سرچ گوگل پس از کلیک کردن حدود ۲۰۰ نفر روی لینک آن در نتایج جستجو، به جایگاه اول حرکت کند. جالب اینجاست که نتایج جستجو برای افرادی با موقعیتهای جغرافیایی مختلف، متفاوت بود. مثلاً این رتبه در کشور آمریکا که بیشتر شرکت کنندگان در آزمایش در آن کشور حضور داشتند ارتقاء یافت اما در کانادا، استرالیا و غیره پایین باقی ماند.
- مقایسه Larry Kim از بالاترین صفحات و وضعیت آنها قبل و بعد از پیاده سازی الگوریتم RankBrain نشان داد که الگوریتم یادگیری ماشینی گوگل رتبه صفحاتی را که کاربران زمان زیادی در آنها صرف نمیکنند، کاهش داد.
- آزمایش Darren Shaw هم تأثیر رفتار کاربران بر جستجوهای محلی را نشان داد.
با توجه به مشخص بودن استفاده از معیارهای تعامل کاربران برای تنظیم نتایج جستجو و تغییر رتبهها در اثر آن میتوان گفت که مسئولان سئو هم باید به دنبال بهینه سازی نرخ تعامل باشند. تعامل منجر به تغییر کیفیت صفحه نمیشود بلکه نشان دهنده ارزش صفحه شما نسبت به سایر نتایج برای جستجوگرها است. به همین دلیل حتی اگر تغییری در صفحات یا بک لینکهای شما ایجاد نشود، اگر رفتار جستجوگرها نشان دهد که سایر صفحات برای آنها بهتر هستند، ممکن است شاهد افت رتبه سایتتان باشید.
از نظر رتبه بندی صفحات وب، معیارهای تعامل مثل یک ابزار بررسی حقایق عمل میکنند. عوامل موضوعی مثل لینکها و محتوا اول از همه رتبه صفحات را مشخص میکنند و بعد از آن معیارهای تعامل قرار دارند و به گوگل نشان میدهند که رتبه بندی را درست انجام داده یا خیر.
تحول نتایج جستجو
وقتی موتورهای جستجو فاقد پیچیدگی و امکانات امروزی بودند، اصطلاح “۱۰ لینک آبی” ابداع شد که ساختار ساده صفحه نتایج جستجو را نشان میداد. هر زمان جستجویی انجام میشد، گوگل صفحهای با ۱۰ نتیجه غیر تبلیغاتی نشان میداد که همگی یک قالب داشتند.
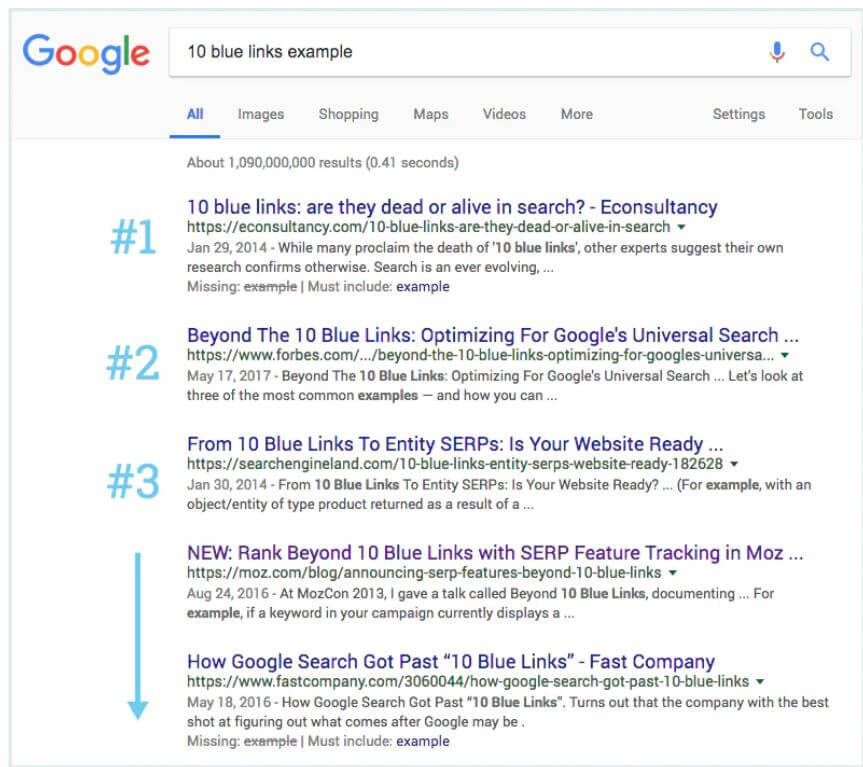
در حوزه سئو، کسب جایگاه اول جام مقدس محسوب میشد اما ناگهان گوگل شروع به اضافه کردن نتایج جدید با فرمتهای مختلف کرد که به آنها امکانات صفحه نتایج جستجو (SERP features) گفته میشود. بعضی از این امکانات به این شرح هستند:
- تبلیغات پرداختی
- Featured snippet یا پاسخ برجسته
- کادرهای “مردم همچنین میپرسند”
- نقشههای محلی
- پنل دانش
- سایت لینکها
و گوگل دائماً در حال اضافه کردن این امکانات است. حتی اخیراً صفحهای با صفر نتیجه را امتحان کرد که در آن فقط گراف دانش نمایش داده میشود و هیچ نتیجهای پایین آن قرار ندارد به غیر از گزینه “مشاهده نتایج بیشتر”.
اضافه شدن این امکانات باعث شد عدهای به دو دلیل دچار وحشت شوند. اول اینکه خیلی از این امکانات جدید باعث میشد نتایج ارگانیک و طبیعی به ردههای پایینتر حرکت کنند. بعلاوه، کاربران کمتری روی نتایج ارگانیک کلیک میکردند چون خود صفحه به خواسته آنها پاسخ میدهد.
اما دلیل انجام این کار توسط گوگل به تجربیات کاربران برمی گردد. رفتار کاربران نشان میدهد که برای بعضی از کوئریها فرمتهای محتوایی خاصی مناسبتر هستند. توجه کنید که چطور امکانات مختلف صفحه نتایج جستجو برای هر کوئری و برای مقاصد مختلف کاربران از جستجو متفاوت است.
| قصد جستجو | قابلیتی که برای آن فعال میشود |
| اطلاعاتی | نتیجه برجسته |
| اطلاعاتی با یک پاسخ | گراف دانش/ پاسخ فوری |
| محلی | نقشه |
| تراکنشی | خرید |
توجه داشته باشید که میتوان پاسخ جستجوگرها را به فرمتهای مختلفی ارائه کرد و ساختار محتوای شما تأثیر چشمگیری بر فرمت مورد استفاده برای نمایش آن در نتایج جستجو دارد.
پیشنهاد میکنم مطلب با عنوان “اسکیما (Schema) چیست و چرا برای سئو مهم است؟” را برای آشنایی با دادههای ساختار یافته مطالعه کنید.
جستجوهای محلی
موتور جستجویی مثل گوگل، ایندکس اختصاصی خودش را دارد که از داخل آن نتایج جستجوهای محلی را ایجاد میکند.
اگر کار سئوی محلی (Local SEO) را برای کسب و کاری انجام میدهید که یک شعبه فیزیکی دارد (مثل دندانپزشکی) یا کسب و کاری که خودش برای بازدید از مشتریان جابجا میشود (مثل لوله کشی) حتماً کسب و کارتان را در فهرست مشاغل گوگل (Google My Business Listing) ثبت و بهینه سازی کنید.
گوگل برای تعیین رتبههای چنین نتایجی سه شاخص دارد:
- میزان تناسب
- فاصله
- برجستگی
میزان تناسب
میزان تناسب یعنی اینکه کسب و کار محلی شما چقدر با آنجه جستجوگران به دنبالش هستند تناسب دارد. برای اطمینان از اینکه کسب و کارتان هر آنچه میتواند را در اختیار مشتریان محلی قرار میدهد مطمئن شوید که اطلاعات آن را به صورت دقیق و کامل پر کردهاید.
فاصله
گوگل از موقعیت مکانی شما برای ارائه بهترین نتایج جستجو استفاده میکند. نتایج جستجوهای محلی به شدت نسبت به مجاورت حساس هستند و اینکه محل جستجوکننده و یا محل مشخص شده در کوئری (اگر جستجوگر آن را درج کرده باشد) در این نتایج تأثیر چشمگیری دارند.
نتایج جستجوهای ارگانیک نسبت به محل جغرافیایی جستجوگر حساس هستند اما به ندرت شبیه به نتایج local pack محسوب میشوند.
برجستگی
با توجه به اینکه برجستگی هم جزء عوامل رتبه بندی محسوب میشود این یعنی گوگل به دنبال رتبه دادن برای کسب و کارهایی است که در دنیای واقعی هم شناخته شده باشند. علاوه بر اعتبار و برجستگی در دنیای واقعی، گوگل برای رتبه دادن به کسب و کارهای محلی یکسری فاکتور از دنیای آنلاین را هم در نظر میگیرد از جمله:
نظرات
تعداد نظرات دریافت شده توسط یک کسب و کار محلی و جو احساسی این نظرات که تأثیری چشمگیر بر رتبه گرفتن دارد.
ارجاع و توصیه
business citation یا business listing مرجعی آنلاین حاوی نام، آدرس و شماره تلفن مشاغل محلی در پلتفرمهای مکانی سازی شده (مثل Yelp، Acxiom، YP، Infogroup، Localeze و غیره) است.
این رتبهها تحت تأثیر تعداد ارجاعات قرار دارند. گوگل این اطلاعات را از منابع مختلف استخراج کرده و به صورت پیوسته شاخص کسب و کارهای محلی خودش را به روزرسانی میکند. وقتی گوگل چندین ارجاع منسجم به نام، محل و شماره تلفن یک کسب و کار پیدا کند اعتماد آن نسبت به اعتبار این دادهها بیشتر میشود. در نتیجه گوگل با درجه اطمینان بیشتری آن کسب و کارها را نمایش میدهد. همچنین گوگل از اطلاعات به دست آمده از سایر منابع وب مثل لینکها و مقالات هم استفاده میکند.
رتبههای ارگانیک
اصول سئو برای کسب و کارهای محلی هم صدق میکند چون گوگل هنگام تعیین رتبه کسب و کارهای محلی، موقعیت سایت در نتایج ارگانیک را هم در نظر میگیرد.
نکته پایانی، تعامل
هر چند گوگل مستقیماً میزان تعامل را جزء فاکتورهای مهم در رتبه بندی ذکر نکرده اما تأثیر این فاکتور به مرور زمان بیشتر میشود. گوگل سعی دارد با استفاده از دادههای لحظهای و بلادرنگ مثل زمانهای محبوب و پرکاربرد و میانگین مدت زمان بازدید، این دادهها را غنیتر کند.
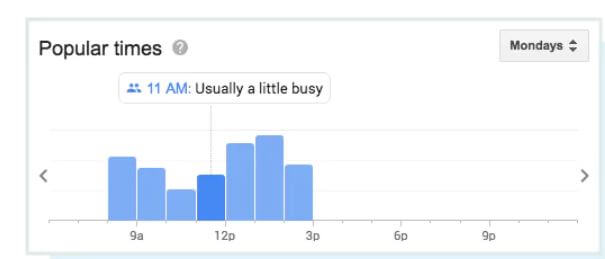
و حتی به کاربران امکان میدهد پرسشهای بیزنسی مطرح کنند.

بدون شک حالا بیشتر از همیشه نتایج محلی تحت تأثیر دادههای واقعی قرار دارند. یعنی واکنش کاربران به نتایج مربوط به کسب و کارهای محلی بسیار مهمتر از ارائه اطلاعات سادهای مثل لینکها و ارجاعات است.
از آنجایی که گوگل به دنبال ارائه بهترین و مرتبطترین نتایج است کاملاً طبیعی است که از دادههای لحظهای و بلادرنگ برای تعیین میزان کیفیت و تناسب محتوا استفاده کند.
هیچکدام از ما از عملکرد داخلی الگوریتمهای گوگل مطلع نیستیم اما با کسب اطلاعات درباره نحوه یافتن، تفسیر، مرتب سازی و رتبه بندی محتوا میتوانیم جایگاه خودمان را در صفحه نتایج جستجو ارتقاء دهیم.
[۱] scrapers
منبع: سایت Moz.com



دیدگاهتان را بنویسید